














| Рубрикатор |  |
 |
| Статьи |  |
ИКС № 10 2014 | |
|
| Михаил ЛЕБЕДЬ | 07 октября 2014 |
Как сделать 100 тысяч транзакций в секунду
Такая высокая производительность базируется на трех китах: совместной обработке данных в многопроцессорных комплексах, виртуализации ресурсов и обеспечении практически одновременного многопользовательского доступа в СУБД.
 В течение последнего года в мире обработки данных произошли два знаменательных события. В октябре 2013-го отмечалось 45-летие разработки концепции системы управления базами данных, а в апреле 2014-го – 50-летие концепции мейнфреймов IBM. В момент своего появления эти концепции были по-настоящему новаторскими. Причем они не только стали основой для многих программно-технических продуктов, но и способствовали – в сочетании с другими мировыми инновациями – переводу на качественно иной уровень применения информационных технологий в бизнесе, науке и управлении. сосуществование двух концепций позволило установить в октябре прошлого года своеобразный рекорд – на одной вычислительной установке удалось достичь уровня производительности свыше 100 тыс. транзакций в секунду*.
В течение последнего года в мире обработки данных произошли два знаменательных события. В октябре 2013-го отмечалось 45-летие разработки концепции системы управления базами данных, а в апреле 2014-го – 50-летие концепции мейнфреймов IBM. В момент своего появления эти концепции были по-настоящему новаторскими. Причем они не только стали основой для многих программно-технических продуктов, но и способствовали – в сочетании с другими мировыми инновациями – переводу на качественно иной уровень применения информационных технологий в бизнесе, науке и управлении. сосуществование двух концепций позволило установить в октябре прошлого года своеобразный рекорд – на одной вычислительной установке удалось достичь уровня производительности свыше 100 тыс. транзакций в секунду*.
За минувшие годы сформировалась целая когорта высокопроизводительных систем обработки данных: DB2, FireBird, IMS, Informix, MS SQL, MySQL, Oracle, PostgreSQL, Sybase SQL, VoltDB. Неоднократно предпринимались попытки сравнить их полезность, тестировались всевозможные операции: выборка данных, запись данных, построение индексов, загрузка процессоров, приемлемое количество одновременно работающих клиентов, продолжительность непрерывной работы системы и т.д. Однако эти системы разные, высокая производительность достигалась в них по-разному, и по-разному она измерялась. Тем не менее в основу упомянутых систем заложены некие общие принципы. Выделение и исследование таких принципов может представлять интерес для разработчиков и специалистов по эксплуатации многопроцессорных систем обработки данных в сферах, связанных, например, с мобильным компьютерным оборудованием, компьютеризованными медицинскими системами, диспетчерским оборудованием авиацентров и т.п.
Многопроцессорный фундамент
Безусловно, основная характеристика вычислительных комплексов, на которых строятся современные высокопроизводительные системы обработки данных, – это многопроцессорность. В комплексах применяются как центральные процессоры общего назначения (CPU, central processing unit), так и различные специализированные процессоры, например: процессоры ввода-вывода, процессоры для поддержки работы Java-программ, процессоры обработки баз данных, процессоры комплексирования и др. Задействование большого количества совместно работающих модулей существенно повышает общую системную производительность, увеличивает количество одновременно выполняемых задач, повышает надежность обработки данных.
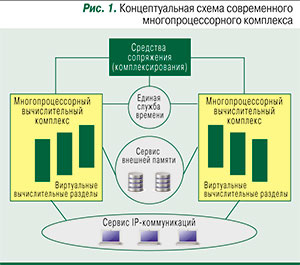 Особую роль в архитектуре комплексов играют процессоры, обеспечивающие комплексирование. На базе этих специализированных процессоров создаются устройства комплексирования, называемые также устройствами сопряжения. Такие устройства представляют собой разделяемую быстродействующую оперативную память большого объема, используемую одновременно несколькими реальными или виртуальными вычислительными установками, объединяемыми в единый комплекс. На них не выполняются никакие иные операции, кроме размещения и выборки разделяемых (совместно используемых) данных. Устройства сопряжения «невидимы» как для операционной системы, так и для приложений.
Особую роль в архитектуре комплексов играют процессоры, обеспечивающие комплексирование. На базе этих специализированных процессоров создаются устройства комплексирования, называемые также устройствами сопряжения. Такие устройства представляют собой разделяемую быстродействующую оперативную память большого объема, используемую одновременно несколькими реальными или виртуальными вычислительными установками, объединяемыми в единый комплекс. На них не выполняются никакие иные операции, кроме размещения и выборки разделяемых (совместно используемых) данных. Устройства сопряжения «невидимы» как для операционной системы, так и для приложений.
Для облегчения управления обработкой разделяемые данные обычно структурируются, и процессоры комплексирования работают со структурами данных. Собственно обработка разделяемых данных осуществляется с помощью специализированных сервисов. Благодаря этим сервисам задачи, использующие данные, размещенные в устройствах сопряжения, могут выполняться на любой вычислительной установке, входящей в комплекс, могут останавливаться, перезапускаться или переключаться с одной установки на другую.
Виртуализация всего и вся
В высокопроизводительной обработке данных нашла широкое применение технология виртуализации, которая затрагивает буквально все составляющие: память, диски, дисплеи, вычислительные установки, вычислительные сети.
Основной вклад в повышение производительности обработки данных вносит виртуализация памяти. В вычислительных системах, предполагающих использование памяти объемом более 4 Гбайт, еще с начала 2000-х была реализована 64-разрядная архитектура, таким образом в настоящее время размер адресуемой виртуальной памяти достигает 264 байт = 16 EB (экзабайт). Как правило, в высокопроизводительных СУБД поддерживаются множественные защищенные виртуальные адресные пространства, объемом до 16 EB каждое.
Виртуализация памяти стала основой для развития виртуальных методов доступа к данным (Virtual Storage Access Method). Эти методы обеспечивают возможность размещения в виртуальной памяти так называемых быстрых баз данных, доступ к которым осуществляется без преобразования данных и без операций ввода-вывода. Также стали возможными организация распределенных файлов и сетевой файловой структуры. Например, в системе обработки данных VoltDB все базы данных размещаются в виртуальной памяти, что обеспечивает производительность более 1 млн транзакций в минуту. Хотя за ненадлежащую надежность эту систему достаточно много критикуют.
В конечном счете, сочетание виртуализации памяти с общим каталогом системных ресурсов при наличии единой системы времени и внешней дисковой памяти, доступ к которой обеспечивает скоростная система каналов ввода-вывода, позволяет создавать на базе многопроцессорных комплексов надежные и высокопроизводительные системы распределенной обработки данных. При этом обеспечивается функционирование не только новых 64-разрядных приложений, но и приложений меньшей разрядности, разработанных в предшествующие годы.
Для поддержки пользовательских рабочих станций (терминалов или персональных компьютеров) в таких системах обработки данных задействуются коммуникационные сервисы TCP/IP. В рамках этих сервисов, помимо базовых средств передачи данных, поддерживаются важнейшие современные протоколы прикладного уровня, включая TELNET, FTP, SMTP и др. Для защиты передаваемых данных сервисы TCP/IP используют встроенные средства шифрования. В качестве обязательных присутствуют развитые средства системного администрирования, а также средства обеспечения информационной безопасности.
Основным путем повышения общей системной производительности, количества одновременно выполняемых задач, уровня надежности вычислений и снижения их себестоимости становится параллельная работа множества приложений с одними и теми же данными.
 Одновременный доступ
Одновременный доступ
Идея, на основе которой разрабатывались системы управления базами данных, заключается в отделении данных от программ, т.е. в отделении объекта от средств управления им. Сконструированные БД позволили получить целостные, полные и непротиворечивые производственные данные с минимальными затратами на их поддержку. Программы, составившие СУБД, обеспечили возможность комплексной параллельной работы множества приложений над одними и теми же данными. При этом поддерживаются как оперативная (пакетная) обработка, так и надежное подключение множества удаленных пользователей.
На ранних этапах многопользовательский доступ к БД таковым по своей сути не являлся: пользователи получали доступ к общим данным последовательно один за другим. Первоначально наименьшим информационным элементом были записи. Когда один пользователь начинал обработку записи, запрос другого пользователя к этой же записи блокировался. На пути сокращения времени блокировки развились такие приемы, как синхронизация и очередизация запросов, организация монопольного или совместного доступа, обязательное завершение начатого действия. К настоящему времени процедуры совместной обработки данных в высокопроизводительных СУБД согласованы в такой степени, что целостность базы не нарушается, действия одной транзакции изолированы от изменяющих действий других транзакций, а все результаты операций достоверны. Если хотя бы одно из простейших действий в рамках транзакции не может быть выполнено, то считается, что транзакция не может быть выполнена, и все действия в рамках этой транзакции автоматически отменяются, в том числе и успешно завершившиеся (делается откат). При этом блокируются только те транзакции, которым требуется доступ именно к ресурсам, изменяемым данной транзакцией, и только на время ее выполнения. Такую организацию уже можно считать настоящим многопользовательским доступом к общей базе данных.
Эффективность многопользовательского доступа усиливается сериализацией транзакций, т.е. одновременным запуском и выполнением множества запросов разных транзакций. Проблемы, возникающие из-за взаимоблокировок и аварийных ситуаций, решаются путем отката соответствующих транзакций и их перезапуском с более низким уровнем сериализации. Сериализация с гарантированным высоким уровнем непрерывности операций обеспечивается при помощи планирования элементарных операций. Например, такие средства планирования, как упреждающие захваты ресурсов, очередизация, синхронизация, логическое разложение ресурсов на наимельчайшие и блокировка только этих наимельчайших объектов, являются настоящими интеллектуальными оптимизаторами транзакций.
Многопользовательский доступ к общим данным устраняет необходимость в какой-либо особой параллельности вычислений на уровне приложений. В настоящее время во многих областях бизнеса и управления вычисления распараллеливаются естественным образом. Такие операции, как обновления банковских счетов, резервирование мест в гостиницах, продажа и регистрация авиабилетов и др., выполняются единообразно по одним и тем же алгоритмам, одна копия программ используется для выполнения множества однотипных транзакций.
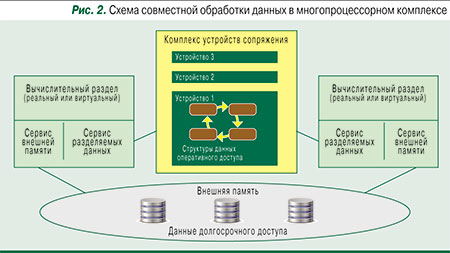
Благодаря многопроцессорной архитектуре комплексов СУБД имеется возможность на одной технической установке организовывать несколько логических вычислительных установок (виртуальных машин) и запускать на каждой из них управляющую программу. Различные управляющие программы, используя средства комплексирования, могут обрабатывать одни и те же данные, имея доступ к ним как на чтение, так и на запись. На одной и той же логической установке кроме обработки баз данных могут выполняться многие иные работы.
В СУБД разные запущенные управляющие программы в комплексе могут обрабатывать одни и те же потоки входных и выходных данных (но не операторских команд). Такие данные называются разделяемыми (совместно используемыми) и размещаются в виде соответствующих структур данных в устройствах сопряжения. Буферизация вводимых данных, размещение их в устройствах сопряжения, выборка их для обработки и выполнение других управляющих функций обеспечиваются уже упоминавшимся особым сервисом обработки разделяемых данных. Одновременное выполнение нескольких управляющих программ СУБД на нескольких логических вычислительных установках комплекса для обработки разделяемых данных позволяет значительно повысить уровень сериализации транзакций. Балансировка нагрузки на различные логические вычислительные установки осуществляется автоматически. Как правило, конечных пользователей интересует только время ответа на их запросы, и внутренняя организация вычислений остается для них невидимой.
Тонкости эксплуатации
При эксплуатации СУБД возникает задача предоставления всех необходимых данных, позволяющих восстановить целостность базы и правильную обработку данных при первоначальном запуске, при запланированной перезагрузке, а также при сбоях программных или технических средств. В процессе работы такая информация собирается в последовательных контрольных точках и фиксируется в системных журналах. Эти журналы архивируются с высокой степенью надежности, а именно: всегда определяются несколько журналов – наборов данных, и пока идет сбор информации в конкретном журнале, заполненные журналы перемещаются в долговременный архив, освобождая место для размещения новой порции системной информации.
Существуют несколько типов запуска СУБД: первоначальный (Cold), запланированный (Warm), аварийный (Emergency) и т.д. При первоначальном запуске форматируются все журналы, данные для рестарта, очереди входных и выходных данных. При запланированном запуске используется текущее состояние всей системной информации. При аварийном запуске выполняются откаты всех незаконченных транзакций, откаты данных в незавершенных изменениях БД и в выходных очередях, данные во входные очереди подкачиваются заново, перезапускаются основные системные процессы СУБД.
Когда в СУБД реализуется автоматический запуск, то система самостоятельно (автоматически) решает, какой тип запуска использовать в зависимости от того, как завершилась предшествующая работа.
Системные журналы в каждом случае предоставят всю необходимую для старта информацию.
____________________________________________________________________________________
*По данным IBM, ее система обработки иерархических баз данных IMS (Informational Management System) продемонстрировала производительность 113 тыс. транзакций в секунду на одной вычислительной установке.