














| Рубрикатор |  |
 |
| Статьи |  |
ИКС № 4 2023 | |
|
| Энди ЛОУРЕНС Ленни САЙМОН | 25 декабря 2023 |
Анализ отказов в ЦОДах
Предотвращение сбоев в работе цифровой инфраструктуры – приоритетная задача для руководителей всех компаний, участвующих в предоставлении ИТ-услуг. Чтобы снизить вероятность повторения отказов ИТ-систем и ЦОДов, важно располагать данными об их типе, частоте и последствиях.
Методология и терминология
Собирать информацию об отказах – дело непростое. Одни аварии широко освещаются в СМИ, другие остаются не известными общественности. Некоторые менеджеры, сотрудники и клиенты ЦОДов могут знать о перебоях в его работе, в то время как другие не будут осведомлены об этом. Кроме того, проблемы, связанные с деградацией сервисов или перебоями в работе, могут не классифицироваться как отказы.
В этом материале использованы данные из разных источников (табл. 1), включая общедоступную информацию (например, опубликованную в СМИ и соцсетях), аналитические исследования Uptime Institute (в частности, глобальный опрос руководителей ИТ-служб и ЦОДов в 2022 г. и исследование отказоустойчивости ЦОДов в 2023 г.), а также другие обезличенные и обобщенные данные, полученные от участников опросов и партнеров Uptime. Отказы в работе ИТ-систем и ЦОДов (далее – отказы) в зависимости от серьезности их последствий мы разделяем на пять категорий (табл. 2).

Табл. 1. Источники информации, используемые Uptime Institute для отслеживания отказов в работе ИТ-систем и ЦОДов

Табл. 2. Классификация отказов по серьезности их последствий
Несколько десятилетий инноваций, масштабные инвестиции и совершенствование процедур эксплуатации в ИКТ-отрасли позволили добиться того, что в целом критически важные ИТ-системы, сети и центры обработки данных стали намного более надежными, чем раньше. Впечатление, что серьезные сбои происходят чаще, обусловлено усилением зависимости экономики и общества от ИТ, а также большей прозрачностью работы ИТ-систем благодаря публикациям в новостных каналах и соцсетях.
Для большинства руководителей ЦОДов и ИТ-служб небольшие перебои в обслуживании на уровне ИТ-систем – частый раздражитель и признак того, что требуются дополнительные внимание и инвестиции. Но в фокусе настоящего отчета находятся более серьезные инциденты (категорий 3, 4 и 5), которые могут иметь тяжелые последствия и требуют детального анализа первопричин, а также корректирующих действий, чтобы снизить вероятность их повторения.
Растущее в последние годы использование облачных сервисов изменило характеристики отказов. Они часто вызваны ошибками ПО или конфигурирования, и это отражает растущую сложность ИТ-систем и обслуживающих их сетей.
Частота и тяжесть отказов
Насколько часто происходят отказы? Увеличивается ли их число? Ответы на эти вопросы зависят от того, кого вы спрашиваете и как ваши респонденты определяют, что такое отказ. Несмотря на эти методологические сложности, данные опросов Uptime Institute, охватывающие большие группы руководителей ЦОДов и ИТ-служб по всему миру, относительно непротиворечивы.
Они свидетельствуют о том, что количество отказов во всем мире увеличивается из года в год по мере роста отрасли. Это увеличение наряду с очевидными последствиями некоторых отключений неизбежно привлекает внимание общественности. Может создаться ложное впечатление, что частота отказов в пересчете на единицу емкости ИТ-систем растет. На самом деле это не так. Число отказов растет не так быстро, как масштабы ИТ-инфраструктуры или глобальная емкость ЦОДов.
В четырех опросах, проведенных в 2020–2022 гг., доля менеджеров ЦОДов, которые столкнулись с перебоями в работе своих объектов, колебалась от 60 до 80%. В целом частота отказов в пересчете на одну площадку (или на одного респондента опроса) устойчиво снижается. В 2022 г. из числа операторов, участвовавших в ежегодном опросе Uptime, о перебоях в работе за последние три года заявили 60%, в то время как в 2021 г. таких операторов было 69%, а в 2020 г. – 78%.
Но мы не хотели бы заявлять о прорывном улучшении ситуации по двум причинам. Во-первых, влияние пандемии COVID-19 на бизнес-климат и на работу ИТ-служб и ЦОДов затрудняет сравнение результатов исследований последних лет. Во-вторых, есть некоторые противоречивые данные (здесь они подробно не обсуждаются), которые требуют дальнейших исследований.
Есть также признаки того, что частота по крайней мере некоторых категорий отказов уменьшается. Uptime Institute классифицирует отказы по шкале от 1 до 5 (см. табл. 2), и в две наиболее серьезные категории (4 и 5) исторически попадал примерно каждый пятый отказ. Но по данным опроса, проведенного в 2022 г., доля этих отказов сократилась до 14% (рис. 1).

Источник: Uptime Institute Global Survey of IT and Data Center Managers, 2022
Рис. 1. Доли различных категорий отказов за последние три года
Какие выводы можно извлечь из полученных данных?
Частота отказов относительно постоянна и высока, несмотря на усовершенствование технологий, ПО и методов физического резервирования. Обусловленные отказами финансовые и/или репутационные издержки оправдывают серьезную обеспокоенность руководителей и регулирующих органов.
Несмотря на шумиху в СМИ, нет никаких свидетельств того, что число отказов увеличивается в сравнении с общим ростом масштабов ИТ-систем – возможно, оно даже медленно снижается. (Uptime Institute проводит дальнейшие исследования по этому вопросу.)
Частота отказов и их продолжительность убедительно свидетельствуют о том, что фактические показатели многих поставщиков не соответствуют соглашениям об уровне обслуживания (SLA). Клиентам не следует рассматривать SLA (или показатели доступности, выраженные тем или иным количеством девяток (99,9…)) в качестве надежной гарантии будущей доступности сервисов.
Анализ данных об отказах затрудняют два фактора. Первый связан с последствиями пандемии: в то время как одни операторы ЦОДов были вынуждены сократить объем технического обслуживания, другие, наоборот, смогли проводить внеплановое дополнительное техобслуживание. Второй – со смещением акцентов с ЦОДов премиум-класса, часто имеющих одну резервную площадку, на более сложные распределенные архитектуры. Хотя последние в конечном счете могут оказаться более устойчивыми, обеспечение отказоустойчивости в больших и сложных сетях ЦОДов еще недостаточно отработано.
Причины отказов
Знание причин отказов имеет решающее значение для их предотвращения в будущем. Большинство инцидентов имеют несколько причин, и, как мы заметили в ходе опросов, понимание их деталей может зависеть от точки зрения конкретного специалиста.
Ежегодные глобальные опросы руководителей ИТ-служб и ЦОДов дают надежный и непротиворечивый набор данных от респондентов, которые, как правило, в деталях осведомлены о работе ЦОДов, но не всегда обладают столь же подробными знаниями обо всех аспектах работы ИТ-систем. Другие исследования Uptime, охватывающие более широкую группу респондентов, могут выявлять другое распределение причин отказов. Поэтому к подобным данным следует относиться аккуратно.
Результаты ежегодного опроса, проведенного Uptime в 2022 г., хорошо согласуются с данными предыдущих лет. Они показывают, что основной причиной отказов на большинстве объектов остаются проблемы с электроснабжением (рис. 2). Как и в предыдущие годы, все остальные причины встречаются гораздо реже. Три другие распространенные причины также неизменны: сбои в системе охлаждения, ошибки ПО/ИТ-систем и проблемы с сетевой инфраструктурой. Частота проблем у сторонних поставщиков – например, у провайдеров SaaS, хостинга и инфраструктурных облачных сервисов – растет, что отражает более интенсивное использование облаков и услуг colocation.

Источник: Uptime Institute Global Survey of IT and Data Center Managers, 2020–2022
Рис. 2. Основные причины отказов в ЦОДах
При опросе более широкого круга специалистов картина несколько меняется. В ежегодном исследовании отказоустойчивости ЦОДов мы также задаем вопросы о наиболее распространенных причинах комплексных сбоев в работе ИТ-служб. Ответы показывают, что проблемы, связанные с сетевой инфраструктурой и коннективностью, встречаются чаще проблем с электроснабжением (рис. 3).

Источник: Uptime Institute Data Center Resiliency Survey, 2023
Рис. 3. Основные причины сбоев в работе ИТ-сервисов за последние три года
Надежность облачных сервисов
Облачные сервисы спроектированы таким образом, чтобы минимизировать вероятность отказов. Для этого крупные провайдеры (такие как Amazon Web Services, Microsoft Azure и Google Cloud) включают в свои решения специальные уровни промежуточного ПО; распределяют нагрузку по системам, сетям и ЦОДам; перенаправляют трафик в обход мест аварий и проблемных сайтов. В целом их архитектуры обеспечивают высокий уровень доступности услуг. Но ни одна архитектура не является абсолютно отказоустойчивой, и многие зарегистрированные сбои можно отнести на счет трудностей управления сложным инфраструктурами облачных провайдеров.
Надежность (и прозрачность) публичных облаков в последние годы стала предметом пристального внимания из-за некоторых громких сбоев в их работе и растущего интереса к запуску в таких облаках критически важных ИТ-сервисов. Концентрация – чрезмерная зависимость от нескольких основных сервисов и ЦОДов, на базе которых эти сервисы предоставляются, – также вызывает озабоченность.
В нашем опросе только каждый десятый респондент счел, что публичные облака достаточно устойчивы для выполнения всех рабочих ИТ-нагрузок. При этом почти каждый пятый (18%) не доверит свои ИТ-нагрузки таким облакам, а около трети (34%) готовы перенести туда только часть нагрузок (рис. 4). Это не те цифры, которые хотели бы видеть облачные провайдеры. Но они вряд ли кардинально изменятся до тех пор, пока провайдеры не смогут предложить больше гарантий прозрачности – и, возможно, новые SLA, предоставляющие критически важным заказчикам больший контроль и компенсацию в случае нарушения соглашений.

Источник: Uptime Institute Data Center Resiliency Survey, 2023
Рис. 4. Устойчивость публичных облаков для критически важных ИТ-нагрузок
Конечно, беспокойство по поводу отказоустойчивости облаков может быть отчасти обусловлено количеством сбоев в работе облачных сервисов, которые попадают в заголовки газет. В нашем исследовании вопросов отказоустойчивости за 2023 г. 42% респондентов (рис. 5) заявили, что за последние три года их организация страдала от перебоев в работе, вызванных проблемами у провайдера, – незначительный рост по сравнению с 2022 г. (39%).

Источник: Uptime Institute Data Center Resiliency Survey, 2023
Рис. 5. Наиболее частые причины отказов из-за поставщиков ИТ-услуг
| Аварии, информация о которых становится общедоступной В дополнение к своим регулярным исследованиям и опросам Uptime Institute отслеживает крупные (или громкие) аварии, о которых сообщают СМИ или другие общедоступные источники. Эта информация иногда отличается от данных опросов. В последние годы СМИ и соцсети все чаще сообщают об отказах ЦОДов, но многие из них незначительны, а информация о них нередко неточна. Поэтому мы не учитываем сообщения о незначительных происшествиях, для которых трудно проверить детали и которые не привели к серьезным финансовым потерям, сбоям в работе или потере репутации.  Абсолютное число серьезных аварий, о которых публично сообщалось, сократилось за последние четыре года. Но неясно, вызвано это технологическими изменениями, изменениями в работе ЦОДов или другими факторами – хотя пандемия COVID-19, может быть, ослабила последствия отказов в 2020 г.  Собранные нами данные позволяют предположить, что каждый год по всему миру, вероятно, будут происходить 10–20 серьезных аварий в области ИТ, которые приведут к крупным финансовым потерям, сбоям в работе компаний, потере репутации или даже к гибели людей. Публично зафиксированные или заявленные перебои в работе ИТ-систем имеют разные причины, но демонстрируют и некоторые закономерности. Так, за последние два года кибератаки и программы-вымогатели стали регулярной и все более частой причиной перебоев. На их долю пришлось 11% публично зарегистрированных отказов в 2022 г. (в 2021 г. – 8%) – см. рисунок ниже. Среди известных жертв были оператор ЦОДа и международная газета. 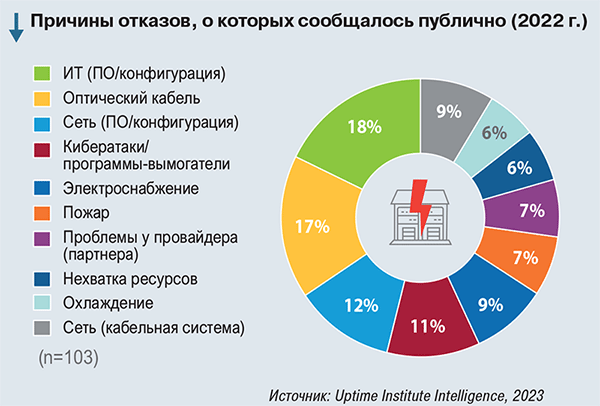 Атаки программ-вымогателей часто приводят к длительному отключению значительной части цифровой инфраструктуры организации. Из-за заражения систем и нарушения целостности данных организациям приходится перестраивать системы и базы данных. Потеря информации при таких инцидентах – обычное дело. Внедрение стандартных операционных систем для управления инженерным оборудованием ЦОДов и более широкое использование средств удаленного мониторинга значительно повышают риск нарушений безопасности в дата-центрах. Чем больше рабочих ИТ-нагрузок передается на аутсорсинг внешним поставщикам, тем больше громких аварий приходится на их долю. Начиная с 2016 г. на провайдеров и коммерческие ЦОДы пришлось две трети (66%) всех отказов, о которых сообщалось публично. И эта доля увеличивается из года в год: в 2021 г. – 70%, а в 2022 г. – уже 81%. Причем сильнее всего выросло количество отказов из-за отключения услуг связи, в то время как число сообщений о перебоях в работе облачных сервисов сократилось. Отчасти это вызвано высокой зависимостью почти всех услуг от телекоммуникаций, но также и тем, что телеком-операторы перешли от дорогостоящих проприетарных систем к более доступным компонентам и архитектурам. |
Окончание следует.
Энди Лоуренс, исполнительный директор по исследованиям, Uptime Institute
Ленни Саймон, старший научный сотрудник, Uptime Institute
Печатается с разрешения Uptime
Institute.
Заметили неточность или опечатку в тексте? Выделите её мышкой и нажмите: Ctrl + Enter. Спасибо!