
















| Рубрикатор |  |
 |

Реклама
| Статьи |  |
ИКС № 3 2020 | |
|
| Николай НОСОВ | 09 сентября 2020 |
Аварийное восстановление и облака
Современный бизнес – непрерывная обработка цифровых данных, потеря которых приводит к авариям, остановке, экономическому ущербу, а в худшем случае – к гибели людей. Поэтому так важны планы, регламенты и инструменты аварийного восстановления данных и ИТ-инфраструктуры.
Остановка – и тебя безнадежно обогнали конкуренты, в тебе начали сомневаться заказчики и партнеры-контрагенты. Нельзя прервать работу доменной печи или сети связи. Если у банка три дня не проходят платежи – ЦБ отбирает лицензию.
Стелим соломку
Пожар, землетрясение, атака хакеров, техническая неисправность оборудования – от неприятностей не застрахован никто. Более того, аварией может стать не только пожар или наводнение, но и менее значительное происшествие, например, когда провалился фальшпол и одна стойка упала.
«Знал бы, где упасть, соломку бы подстелил», – гласит известная поговорка. Ответственно относящиеся к работе компании думают, где могут «упасть», и «подстилают соломку» – уделяют внимание непрерывности бизнеса, способности организации даже после разрушительного инцидента продолжать поставлять продукцию или оказывать услуги на приемлемом уровне. Главное – знать, что делать в той или иной ситуации, иметь план аварийного восстановления, включающий пошаговый сценарий действий персонала: кому и по каким телефонам звонить, какое оборудование подключать, какие программы запускать. Первый шаг – оценить аварийную ситуацию, понять, что случилось, по какому сценарию произошла авария. Возможны частичная или полная потеря оперативных данных, выход из строя вычислительного оборудования, сети передачи данных, ЦОДа, перебои энергоснабжения или проблемы с персоналом.
Заранее уполномоченные сотрудники на основании информации дежурных смен пытаются идентифицировать аварийный сценарий, принимают решение об активации частных планов аварийного восстановления. Решение доводится до руководителей подразделений и групп, отвечающих за реализацию плана, которые, в свою очередь, имеют четкие пошаговые документированные и утвержденные инструкции о том, кто что делает и кто за что отвечает.
В утвержденных документах, как правило, содержатся параметры RPO (Recovery Point Objective), т.е. максимальный период времени, потерю данных за который можно считать допустимой, и RTO (Recovery Time Objective), время восстановления работы (см. рисунок).
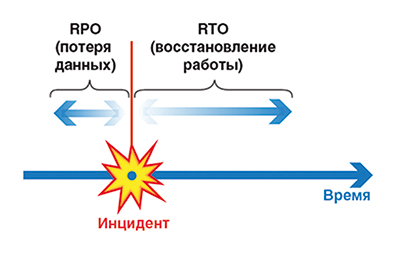
Параметры RPO и RTO
Допустимые значения RTO и RPO устанавливаются в процессе планирования непрерывности бизнеса с учетом целевого времени восстановления конкретных бизнес-процессов (и соответственно поддерживающих их ИТ-сервисов). В зависимости от заданных RPO и RTO выбираются решения для аварийного восстановления (Disaster Recovery, DR) данных, вычислительной и сетевой инфраструктуры, которые включают в себя политики, инструменты и процедуры восстановления или поддержки жизненно важной технологической инфраструктуры/системы после стихийного или антропогенного бедствия.
Подальше положишь – поближе возьмешь
Самое очевидное решение на случай аварии, – дублирование. Уже довольно популярна схема с двумя серверами, объединенными в кластер. Вышел из строя один сервер – нагрузка автоматически переносится на другой, работающий в режиме «горячего» резерва с синхронным отслеживанием изменений на первом. Возможны варианты, когда часть нагрузки постоянно работает на одном сервере кластера, часть – на другом и соответственно для разных задач разные серверы выступают в качестве основного и резервного.
Еще надежней вариант с двумя СХД, особенно с синхронной репликацией данных, до минимума снижающей RPО. Если каждый сервер кластера связан с каждой СХД, работа остановится лишь в случае выхода из строя дублирующих устройств.
Это хорошо, но недостаточно. Ситуация с одновременным отказом дублирующих устройств в одной серверной не такая уж редкость. В банке, где я долгое время работал, серверная находилась на верхнем этаже под крышей. В сильную жару крыша нагревалась, кондиционеры не справлялись с нагрузкой и выходили из строя. Когда температура в серверной поднималась до критической отметки, оба сервера кластера выключались. Приходилось в авральном режиме заниматься откачиванием горячего воздуха, дополнительно устанавливая напольные кондиционеры. Работа банка на это время останавливалась, ведь на кластере размещалась АБС.
Пожар в серверной, перебои с электропитанием, обрыв линии связи – в этих случаях дублирование оборудования в одной серверной не поможет. Надежнее разместить дубли критически важных для бизнеса систем на другой площадке, например, создав растянутый кластер из серверов, расположенных в разных ЦОДах. Скажем, чтобы в Москве гарантированно иметь независимое электропитание, можно выбрать дата-центры на разных берегах Москвы-реки.
.jpg) Территориальная разнесенность дата-центров – важный критерий для сценариев с низкими значениями RPO/RTO, а также с рисками природных бедствий и аварий на объектах инфраструктуры. В российских условиях нормой считается расстояние между объектами от 30 км, для стран с большей вероятностью природных катаклизмов (например, США) – обычно от 140 км. Александр Тугов, директор по развитию услуг, Selectel |
Для восстановления информационной системы после аварии можно задействовать как свои, так и арендованные дата-центры – с арендой площадей ЦОДа по модели colocation для собственного оборудования, арендой физического оборудования дата-центра либо вообще с использованием облачных услуг провайдера.
«Холодно», «теплее», «горячо»
Разнесение площадок по регионам поможет решить проблему выхода из строя ЦОДа из-за стихийных бедствий: землетрясений, наводнений, ураганов, цунами. Разнесение по странам призвано уберечь от последствий политической нестабильности. Однако из-за ограниченной скорости прохождения сигнала и пропускной способности каналов связи придется отказаться от синхронной репликации. Увеличивается RPO, резервное копирование становится «теплым» или даже «холодным».
Выбор решения зависит от конкретных задач и величины потерь вследствие простоя информационных систем. Иметь в «горячем» резерве ЦОД с синхронной репликацией всех данных хорошо, но очень дорого и, как правило, экономически не оправдано. Чаще на случай аварии достаточно иметь резервную копию (бэкап) и площадку для разворачивания резервного ЦОДа и восстановления системы из бэкапа.
Традиционные подходы к Disaster Recovery предполагают наличие у компании резервного ЦОДа и одного из трех вариантов резервирования: «холодного», «теплого» или «горячего». Границы между этими терминами эксперты понимают по-разному, в общем случае исходя из времени, требуемого на восстановление.
«Холодное» резервирование предполагает наличие резервной площадки (серверного помещения или ЦОДа), оснащенной необходимыми инженерными установками, где можно оперативно развернуть ИТ-оборудование для запуска резервной системы. Часть такого оборудования может храниться на складе, часть – закупаться или арендоваться по мере необходимости. Как правило, каналы связи в «холодный» ЦОД заводятся заранее, но активация телекоммуникационных сервисов производится только после принятия решения о его запуске. Понятно, что время запуска такого ЦОДа (другими словами, значение RTO процедуры Disaster Recovery) достаточно велико (может превышать неделю).
В случае «теплого» резервирования альтернативная площадка оснащается всем необходимым ИТ-оборудованием; каналы подключения к интернету и корпоративной WAN-сети находятся в активном состоянии. На «теплой» площадке имеется резервная копия данных: актуальность данных поддерживается путем физической перевозки резервных копий на лентах или организацией бэкапа по сети передачи данных из основного дата-центра. Типовое значение RTO для процедуры Disaster Recovery при «теплом» резервировании превышает день.
При «горячем» резервировании альтернативная площадка представляет собой полное «зеркало» основного ЦОДа. Если ЦОДы работают по схеме active – active, данные в них обновляются синхронно, а в менее дорогостоящей схеме active – passive выполняется асинхронная репликация. Репликации осуществляются на уровне системы хранения данных (функция синхронной репликации поддерживается большинством СХД даже среднего уровня), на уровне сервера или приложения, например СУБД (включая продукты Oracle, Microsoft SQL Server, MySQL, PostgreSQL). В работе могут быть задействованы оба ЦОДа с балансировкой и распределением нагрузки между ними.
При синхронной репликации приложения в реальном времени записывают данные сразу на обе площадки географически растянутого кластера. Чтобы приложения не «тормозили», время отклика должно составлять порядка 5 мc. За это время второй ЦОД должен получить информацию и подтвердить ее получение. Время прохождения сигнала зависит от длины проложенного оптического кабеля. По оценке руководителя направления СХД «Инфосистемы Джет» Романа Харыбина, такое время отклика возможно, если ЦОДы удалены друг от друга не более чем на 30–50 км. Обычно расстояние между дата-центрами при «горячем» резервировании с синхронной репликацией стараются ограничить 25–30 км.
При асинхронной репликации расстояния не так критичны, зато важна полоса пропускания, выдерживающая поток данных между площадками. Определить полосу пропускания нужно еще до заключения договора аренды или строительства нового ЦОДа.
Помимо данных, используемых приложениями, между площадками должны постоянно синхронизироваться настройки ИТ-оборудования, версии ОС, обновления системы безопасности и пр. При наличии «горячего» резервного ЦОДа значение RTO может ограничиваться минутами. Но из трех перечисленных вариантов резервирования этот вариант самый дорогостоящий в реализации и обслуживании.
В каждом из трех вариантов требуется иметь в резерве удаленную площадку с определенным набором оборудования, что само по себе стоит дорого, особенно если компания решает сама строить и обслуживать такую площадку (а не использовать услуги colocation). В случаях «теплого» и «горячего» резервирования предполагается наличие дорогостоящего ИТ-оборудования (стоимость которого может на порядок превышать стоимость инженерных систем ЦОДа), которое будет простаивать в ожидании катастрофы. Неудивительно, что до недавнего времени системы Disaster Recovery могли себе позволить только очень богатые организации, как правило, из финансового сектора. С появлением и распространением технологий виртуализации, а особенно с появлением услуг облачного резервного копирования и аварийного восстановления схемы Disaster Recovery становятся доступными все более широкому кругу заказчиков.
Очень холодно, прямо ледник
Традиционный способ сохранения данных на случай аварийной ситуации – создание резервных копий. Без резервного копирования (бэкапа) невозможно представить работу бизнеса – даже в самом маленьком предприятии важная информация копируется как минимум на флешку.
По сравнению со схемами с резервным ЦОДом обычный бэкап – дешевый, но менее катастрофоустойчивый вариант восстановления бизнес-процессов. Вычислительная и сетевая инфраструктуры не дублируются – данные копируются на носители в том же или стороннем дата-центре и вновь переносятся на оборудование основного дата-центра после ликвидации последствий аварии и возобновления работы его инфраструктуры.
 Резервное копирование развивается вслед за лавинообразным ростом объема хранимых данных. Данные становятся все более ценным и невосполнимым активом: использование первичных документов понемногу отмирает, остаются только электронные копии, которые нужно защищать от потери. В России, в отличие от остального мира, предпочтение отдается собственным ЦОДам. Тенденция использовать две или три площадки сохранится. Сейчас, когда многие компании пересматривают ИТ-бюджеты, выбор будет смещаться в сторону аутсорсинговых услуг. В краткосрочной перспективе они обходятся дешевле. Роман Харыбин, руководитель направления СХД, «Инфосистемы Джет» |
Копировать можно наборы файлов, базы данных, операционную систему (файлы ОС), диски или дисковые тома целиком (посекторно или поблочно). Для хранения используются диски, ленты или виртуализированные носители – виртуальные диски виртуальных машин (блочные хранилища), файловые и объектные хранилища.
Резервное копирование отдельных систем позволяет восстановить работу после ошибочных действий персонала или атак злоумышленников, например, с помощью вирусов-шифровальщиков. Часто резервные копии используются как тестовые базы для разработчиков. Бэкапы стоит периодически проверять на возможность восстановления, чтобы не столкнуться с ошибкой в критической ситуации.
Часть старых резервных копий отправляют в архив для длительного хранения. При необходимости система может быть восстановлена из архива, но поскольку вероятность такого события мала и снижается с возрастом резервной копии, архивы записывают на дешевые медленные носители. С этой точки зрения архивирование можно рассматривать как «очень холодное» резервирование. Не зря в AWS хранилище такой информации называют Glacier (ледник). В архив отправляют и отдельную важную, например, отчетную информацию, которую нужно хранить определенное время в соответствии с политиками компании или требованиями законодательства. Это информация имеет самостоятельную ценность для использования в будущем и не предназначена для
восстановления.
Заметили неточность или опечатку в тексте? Выделите её мышкой и нажмите: Ctrl + Enter. Спасибо!